前回までの処理手順を踏襲して、今回は新しいデータで分析を行ってみます。家電量販店等で並んでいるマッサージ機のデータを用いてみます。Fターム「4C100」の2006年以降出願分になります。処理内容はおおむね前回まで説明した内容と同じですので、Jupyter Notebookの画面のみで説明は飛ばしていきます。
import pandas as pd
import numpy as np
df1 = pd.read_excel('patentdata2.xlsx')
df1.head()
df1['公報番号'].groupby(df1['出願日'].dt.year).count()
出願年毎の出願件数データになります。後で、グラフ作成に用います。
apns = df1['出願人'].map(lambda x: x.split(";"))
ser1 = pd.Series(np.hstack(apns.values))
unique_apns = ser1.str.strip().unique()
unique_apns.sort()
def filter_df_by_apn(df, apn):
apn_df = df.loc[df['出願人'].map(lambda x: apn in x)].copy()
apn_df['出願人'] = apn
return apn_df
apn_df_list =[filter_df_by_apn(df1, apn) for apn in unique_apns]
df2 = pd.concat(apn_df_list)
df2 = df2.loc[:,['公報番号','出願人','出願日']]
df2.sort_values('公報番号', inplace=True)
df2.head()
df2['公報番号'].groupby([df2['出願人'], df2['出願日'].dt.year]).count()
import difflib as diff
for (str1, str2) in [
(str1, str2)
for str1 in unique_apns
for str2 in unique_apns
if str1 < str2
]:
# 類似度を計算、0.0~1.0 で結果が返る
s = diff.SequenceMatcher(None, str1, str2).ratio()
if s > 0.7:
print (str1, "<->", str2)
print ("match ratio:", s, "\n")
df2.loc[df2['出願人'] == 'エレクトロメド,インコーポレイテッド', '出願人'] = 'エレクトロメド・インコーポレイテッド'
df2.loc[df2['出願人'] == 'エレメメディカルインコーポレイテッド', '出願人'] = 'エレメ・メディカル・インコーポレイテッド'
df2.loc[df2['出願人'] == 'コーニンクレッカフィリップスエヌヴェ', '出願人'] = 'コーニンクレッカフィリップスエレクトロニクスエヌヴィ'
df2.loc[df2['出願人'] == 'タイコヘイルスケアグループエルピー', '出願人'] = 'タイコ・ヘルスケアー・グループ・エルピー'
df2.loc[df2['出願人'] == 'パナソニックIPマネジメント株式会社', '出願人'] = 'パナソニック株式会社'
df2.loc[df2['出願人'] == '光▲いく▼金▲屬▼有限公司', '出願人'] = '光▲いく▼金屬有限公司'
df3 = df2['公報番号'].groupby([df2['出願人'], df2['出願日'].dt.year]).count()
df2['公報番号'].groupby(df2['出願人']).count().nlargest(10)
出願人のTOP10件数です。
fts = df1['Fターム'].map(lambda x: x.split(';'))
ser2 = pd.Series(np.hstack(fts.values))
unique_fts = ser2.str.strip().unique()
unique_fts.sort()
def filter_df_by_ft(df, ft):
ft_df = df.loc[df['Fターム'].map(lambda x: ft in x)].copy()
ft_df['Fターム'] = ft
return ft_df
ft_df_list =[filter_df_by_ft(df1, ft) for ft in unique_fts]
df4 = pd.concat(ft_df_list)
df4 = df4.loc[:,['公報番号','Fターム','出願日']]
df4.sort_values('公報番号', inplace=True)
df4.head()
df5 = df4.copy()
df5['Fターム'] = df5['Fターム'].str[0:5]
df5.head()
df5 = df5.drop_duplicates()
df5.head()
df6 = pd.merge(df2, df4, on='公報番号')
df6.head()
分割した出願人データと分割したFタームデータを合体させました。出願日が重複しているのでxやyのラベルが付加されていますが気にしないでください。
df4['公報番号'].groupby(df4['Fターム']).count().nlargest(10)
FタームのTOP10件数です。
df7 = df6[(df6['出願人'].isin(df2['公報番号'].groupby(df2['出願人']).count().nlargest(10).index)) & (df6['Fターム'].isin(df4['公報番号'].groupby(df4['Fターム']).count().nlargest(10).index))]
df8 = df7.pivot_table(index='出願人', columns='Fターム', values='公報番号', aggfunc='count', margins=True)
df8 = df8.sort_values(by=["All"], ascending=False)
df8 = df8.sort_values(by=["All"], axis=1, ascending=False)
df8 = df8.drop("All", axis=1)
df8 = df8.drop("All", axis=0)
df8
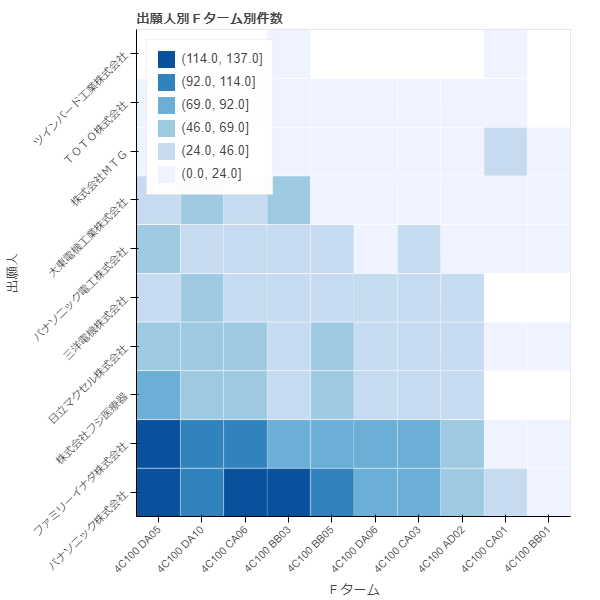
出願人別Fターム別出願件数表です。
df9 = df2[df2['出願人'].isin(df2['公報番号'].groupby(df2['出願人']).count().nlargest(10).index)]
df9 = df9.pivot_table(index=df9['出願日'].dt.year, columns='出願人', values='公報番号', aggfunc='count')
df9
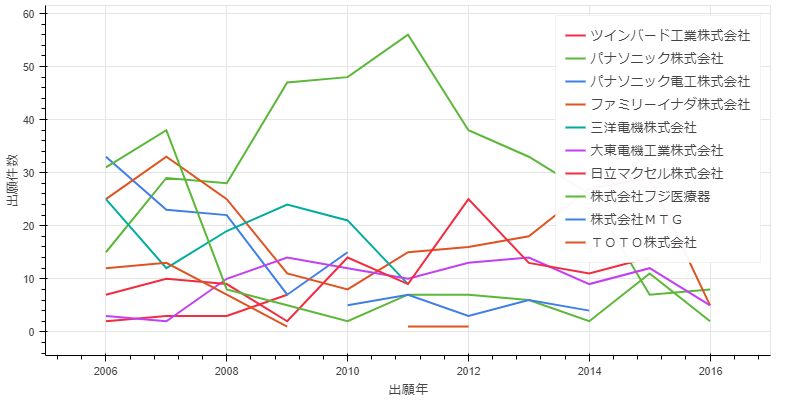
出願人別出願件数推移です。
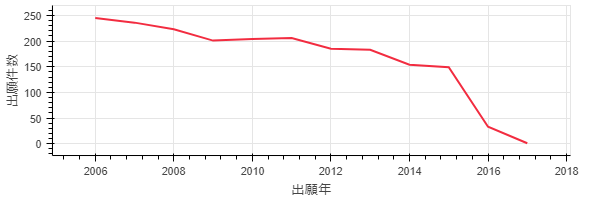
ここまでで、基礎的な件数データの準備は終わったので、グラフを書いていきます。今回はbokehを使っていきます。まずは、集合全体での出願年別出願件数推移から。
from bokeh.charts import output_notebook, Bar, Line, HeatMap, show
from bokeh.palettes import RdYlGn6
output_notebook()
p1 = Line(df1['公報番号'].groupby(df1['出願日'].dt.year).count(), plot_width=600, plot_height=200, legend = False)
p1.xaxis.axis_label = '出願年'
p1.yaxis.axis_label = '出願件数'
show(p1)
次に、上位の出願人別出願年別出願件数推移を作成します。
p2 = Line(df9, plot_width=800, plot_height=400)
p2.xaxis.axis_label = '出願年'
p2.yaxis.axis_label = '出願件数'
p2.legend.location = "top_right"
show(p2)
count3 = []
for x in df8.apply(tuple):
count3.extend(x)
data = {
'出願人': list(df8.index) * len(df8.columns),
'Fターム': [item for item in list(df8.columns) for i in range(len(df8.index))],
'件数': count3,
}
p3 = HeatMap(data, x='Fターム', y='出願人',values='件数', title='出願人別Fターム別件数', stat=None)
show(p3)
こんな感じで、Jupyter Notebook上でグラフ作成まで行うこともできます。前回の記事でも述べましたが、データフレームはExcelに出力することもできるので、Jupyter Notebook上ではなくExcel上でグラフ作成することもできます。