さて、前回までで、母集合の主要な数値指標等を見てきました。
市場としては椅子タイプが牽引してきて、最近は、椅子タイプの安価版としてシートタイプが出てきていること。上位の出願人はおおむねこの椅子タイプを中心に出願を行っており、市場でのシェア上位も上位出願人と合っているといった内容でした。
これからマッサージ機市場に参入する方策を検討しているというシチュエーションでしたので、この椅子タイプに参入していくプランは描きにくいところです。したがって、椅子タイプを外して出願動向を見て、参入の方策を検討していくことにしましょう。
マッサージ機のFターム4C100を見るとCA03からCA09が家庭用の椅子タイプに対応するようです(CA11とCA12も椅子タイプの下位分類ですが、普通の家庭用の椅子タイプからは外れると考えました)。これらCA03からCA09を除外した集合を作ってその数値指標を見ていきましょう。
下記のようにCA03からCA09をFタームに含む案件の公報番号のリストCA03list及び含まない案件のリストNOTCA03listを作成します。
CA03list = df1.loc[df1['Fターム'].str.contains('(4C100 CA03|4C100 CA04|4C100 CA05|4C100 CA06|4C100 CA07|4C100 CA08|4C100 CA09)'), '公報番号']
NOTCA03list = df1.loc[~df1['Fターム'].str.contains('(4C100 CA03|4C100 CA04|4C100 CA05|4C100 CA06|4C100 CA07|4C100 CA08|4C100 CA09)'), '公報番号']
df10 = df2[df2['公報番号'].isin(CA03list)]
df11 = df2[df2['公報番号'].isin(NOTCA03list)]
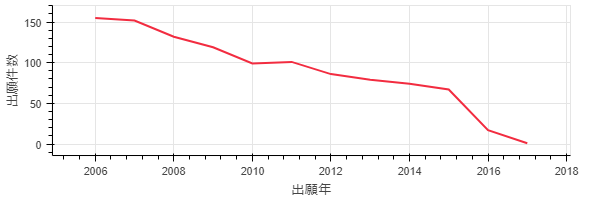
p3 = Line(df10['公報番号'].groupby(df10['出願日'].dt.year).count(), plot_width=600, plot_height=200, legend = False)
p3.xaxis.axis_label = '出願年'
p3.yaxis.axis_label = '出願件数'
show(p3)
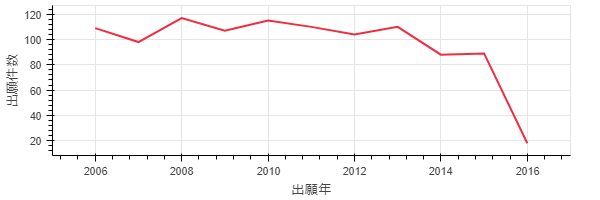
p4 = Line(df11['公報番号'].groupby(df11['出願日'].dt.year).count(), plot_width=600, plot_height=200, legend = False)
p4.xaxis.axis_label = '出願年'
p4.yaxis.axis_label = '出願件数'
show(p4)
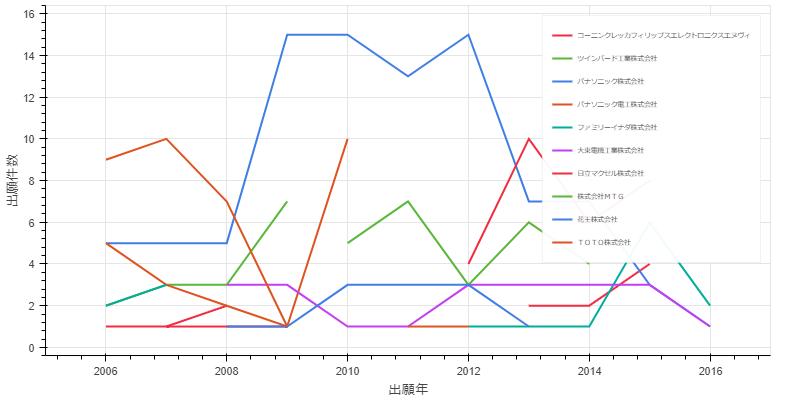
df12 = df11[df11['出願人'].isin(df11['公報番号'].groupby(df11['出願人']).count().nlargest(10).index)]
df12 = df12.pivot_table(index=df12['出願日'].dt.year, columns='出願人', values='公報番号', aggfunc='count')
df12
p5 = Line(df12, plot_width=800, plot_height=400)
p5.xaxis.axis_label = '出願年'
p5.yaxis.axis_label = '出願件数'
p5.legend.location = "top_right"
p5.legend.label_text_font_size = '5pt'
show(p5)
df13 = df6[df6['公報番号'].isin(NOTCA03list)]
df14 = df13[(df13['出願人'].isin(df11['公報番号'].groupby(df11['出願人']).count().nlargest(10).index)) & (df13['Fターム'].isin(df13['公報番号'].groupby(df13['Fターム']).count().nlargest(10).index))]
df15 = df14.pivot_table(index='出願人', columns='Fターム', values='公報番号', aggfunc='count', margins=True)
df15 = df15.sort_values(by=["All"], ascending=False)
df15 = df15.sort_values(by=["All"], axis=1, ascending=False)
df15 = df15.drop("All", axis=1)
df15 = df15.drop("All", axis=0)
df15
count3 = []
for x in df15.apply(tuple):
count3.extend(x)
data = {
'出願人': list(df15.index) * len(df15.columns),
'Fターム': [item for item in list(df15.columns) for i in range(len(df15.index))],
'件数': count3,
}
p6 = HeatMap(data, x='Fターム', y='出願人',values='件数', title='出願人別Fターム別件数', stat=None)
show(p6)

df16 = df13.loc[df13['Fターム'].str.contains('(4C100 DA00|4C100 DA01|4C100 DA02|4C100 DA03|4C100 DA04|4C100 DA05|4C100 DA06|4C100 DA07|4C100 DA08|4C100 DA09|4C100 DA10|4C100 DA11|4C100 DA12|4C100 DA20)')]
df16 = df16[(df16['出願人'].isin(df11['公報番号'].groupby(df11['出願人']).count().nlargest(10).index))]
df17 = df16.pivot_table(index='出願人', columns='Fターム', values='公報番号', aggfunc='count')
count3 = []
for x in df17.apply(tuple):
count3.extend(x)
data = {
'出願人': list(df17.index) * len(df17.columns),
'Fターム': [item for item in list(df17.columns) for i in range(len(df17.index))],
'件数': count3,
}
p7 = HeatMap(data, x='Fターム', y='出願人',values='件数', title='出願人別Fターム別件数', stat=None)
show(p7)
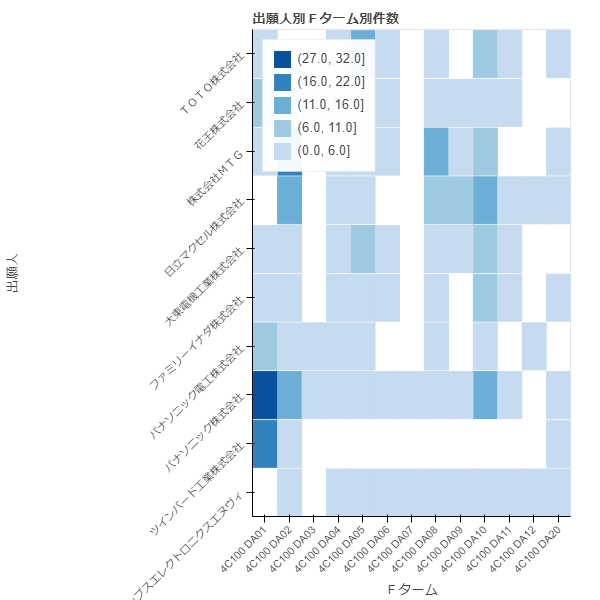
DA07:乳房とDA12:体腔が少なく、DA01-02の頭が多く次いで、DA10の脚が次いで多いといった傾向が見られます。体腔はどのようにマッサージするのか分かりませんが、何件かある公報には書いてあるのでしょう。この情報を元に「手持ち」で「手のひら」とか具体的なアイデアを様々な部署と情報交換して検討していこう。そんな感じでとりあえずの分析を終了します。
いかがでしょうか、多少具体的なイメージでマッサージ機を事例にJupyterを用いた分析について解説してきました。何回か順に分けた説明になったため、Jupyter上での操作内容としては少々煩雑になっています。実際に作業を行う場面では繰り返し行うデータフレームの操作は関数として定義して呼び出して使った方がすっきりして良いと思います。