前回にひき続いてフリーのテキストマイニング&可視化環境を、特許分析に利用することに関して簡単に紹介していきます。今回はKH Coderです。日本語及び英語の処理分析に対応しています。
KH Coderはこちらのサイトから入手できます。先ずは、チュートリアル等をひと通り試してみるのが良いと思います。
特許の分析を行う際には読み込むデータが必要ですが、今回は任天堂のゲーム機の関連の特許要約で行ってみます。
次のようなデータです。
画像から検出される所定の物体または図柄の位置の微細なブレを防止すること。画像から所定物体または所定図柄の位置を順次検出する。そして、第1画像から検出された当該画像上での所定物体または所定図柄の位置と、当該第1画像以前に取得された第2画像から検出された当該画像上での上記所定物体または所定図柄の位置に基づいて、当該所定物体または所定図柄の移動量を計算する。そして、上記移動量が第1閾値未満である場合には、上記第1画像から検出された当該画像上での上記所定物体または所定図柄の位置を、上記第2画像から検出された当該画像上の上記所定物体または所定図柄の位置へと補正する。
画像から所定の物体または図柄を高い精度で検出できるようにすること。まず、撮像装置から取得した画像から、物体または物体に表される図柄の輪郭を表す一連のエッジ画素を検出する。そして、検出された一連のエッジ画素に基づいて複数の直線を生成し、当該複数の直線に基づいて上記輪郭の頂点を検出する。さらに、検出された頂点に基づいて上記撮像装置と上記物体との相対的な位置および姿勢を算出し、当該位置および姿勢に基づいて、仮想空間内の仮想カメラを設定する。そして、当該仮想カメラで仮想空間を撮影することにより得られる仮想空間画像を表示装置に表示させる。
・・・
こんな感じで、1件の特許の要約毎に改行を入れたテキストファイルを用意します。出願人や出願日等の書誌データも読み込ませることは出来ますが、今回は省きます。尚、KH Coderに読み込ませる日本語データは全角のみを推奨(半角文字混じりは推奨しない)です。
まずは、チュートリアルの「こころ」と同様に、メニューから「プロジェクト」→「新規」を選択して、準備したテキストデータを取り込み対象に設定して、「前処理」→「前処理の実行」を選択します。この前処理が完了した後に、「ツール」→「抽出語」→「抽出語リスト」で、上位語をチェックして、例えば「ゲーム」、「手段」、「所定」のような頻出はしているが、一般的過ぎて分析には意味がないかもしれない言葉をチェックしたり、自身の意図に反して分割されている言葉をチェックします。その後で必要に応じて「前処理」→「語の取捨選択」を選択し、分割しないで強制的に抽出したいキーワード、不要なので使用しないように設定したいキーワードを設定すると良いと思います。
前処理が完了して、データの取り込みが完了した後で、KH Coder上で出来る分析には次のような機能があります。
- 多く出現した語の確認:抽出語リスト、頻出150語の表、抽出語検索(取り込み3で概要説明済み)
- 語と語の結びつきを探る:階層的クラスター分析、多次元尺度構成法、共起ネットワーク、関連語探索、対応分析
- 属性毎の特徴を探る:関連語探索、対応分析
- 内容が似た文書(特許)の群を探る:クラスター分析、自己組織化マップ
このなかで代表的な分析例を見ていきます。
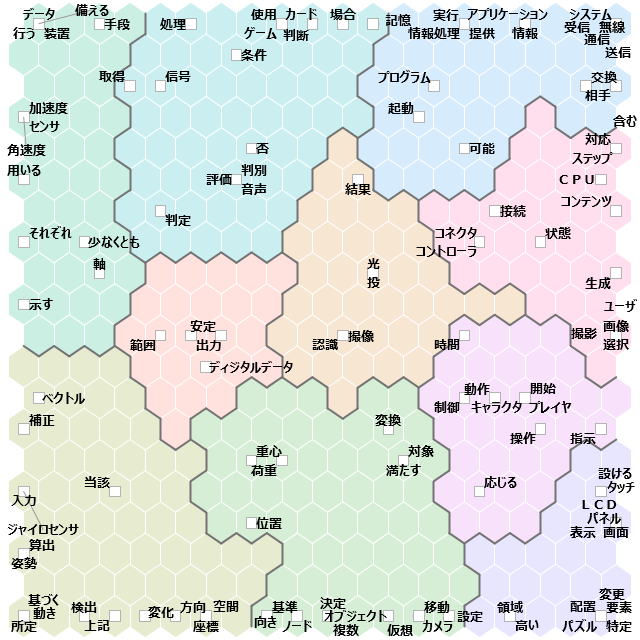
先ずは、階層的クラスター分析、「ツール」→「抽出語」→「階層的クラスター分析」と選択して実行します。出てくる画面で条件設定して「OK」で、次のような図が作成される。良く一緒に出現する語が上下方向で近くに配置され同一色が設定されています。

階層的クラスター分析の設定画面での設定項目ですが、今回のような読み込みデータの場合には、集計単位:「文」(1文単位で一緒に出現することが多い語の集計)か「段落」(1特許単位で一緒に出現することが多い語の集計)を推奨します。また、最小出現数(この程度の回数は出現している語でなければ分析対象としない)、最大出現数(この程度以上出現する語はありふれた語なので分析対象としない)は適宜調整して設定します。抽出語リスト等の数値を参考にすると良いと思います。設定後に左下のチェックボタンを押すと対象となる語の数が参考表示される多分200前後がちょうど良いと思いますが、お好みで調整下さい。
次は、共起ネットワークです。 「ツール」→「抽出語」→「共起ネットワーク」と選択して実行します。下記画面で条件設定して「OK」で、右のような図が作成される。良く一緒に出現する語が近くに配置され、線で結び付けされる。
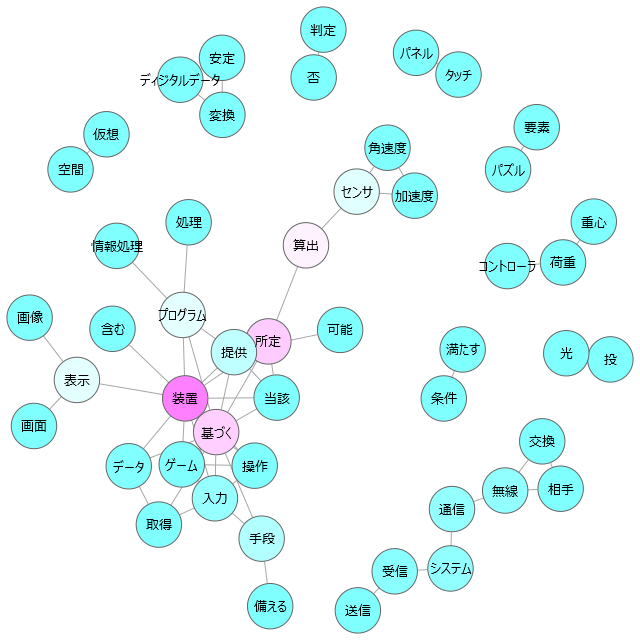
共起ネットワークの設定画面での設定項目については、「集計単位」、「最小/最大出現数」の設定は階層的クラスター分析と同様の設定となります。「共起関係の種類」は、「語-語」を選択すると、良く一緒に出現する語同士の関係を表示。「語-外部変数・見出し」を選択すると外部変数や見出し(h1等のタグで設定したもの)と語の関係を表示(例えば出願人や出願年等と語の関係を分析表示)します。その他、描画数等はお好みで適当に調整して下さい。分析するケースによって最適な数値は違うと思います。
最後は、自己組織化マップです。文書を設定した数に自動区分けするクラスター分析の一種です。「ツール」→「抽出語」→「自己組織化マップ」と選択して実行します。下図のような分類分け図が作成されます。作成に相当の時間を要する場合がありますのでご注意下さい。