さて、前回まではPythonを用いた自然言語処理の入門編ということで、1公報の単語頻度や1公報でのword2vecによる分散表現の取得などを試みてきたわけですが、それでなんなのって感じでしたね。今回は前回までの知識を応用して、多数の公報のテキストデータに対してword2vecでキーワードの分散表現を得る処理を行い、t-SNEを用いて2次元のキーワード分布表示を行うところまで行ってみたいと思います。
まず、最初の難関は多数の公報のテキストデータの取得です。商用特許データベースをお使いの方はそこから好きにダウンロードしていただけばいいですが、暇つぶしの特許テキストマイナーでは無料でなんとかしないといけません。やり方はそれだけで説明が大変な代物なので省きます。個々に工夫してみてください。(e-patentの野崎氏の「特許情報分析とパテントマップ作成入門 改訂版」でもその辺りは有効な手段は示されていません)
では、J-PlatPatの分類検索で入手した現在のZIT分類でヒットする公報の要約・請求項データを集めたテキストを用いた分析を行っていきます。まずは、前回と同様に入手したテキストに対してコマンドラインでMecabによる形態素分析済みのテキストファイル(ZITsw2v.txt’)を作成します。これを用いてword2vecの分析を行っていきます。
from gensim.models import word2vec
data = word2vec.Text8Corpus('ZITsw2v.txt')
model = word2vec.Word2Vec(data, size=200)
out=model.most_similar(positive=[u'データ'])
out
out=model.most_similar(positive=[u'通信'])
out
ここまでは前回と同様の処理です。多数の公報データに基づく分析になった分、前回とは類似キーワードの出方は異なってきます。そしてここからword2vecで処理したキーワードのベクトル表現の分布を2次元で可視化する処理を行っていきます。word2vecは各キーワードが200次元のベクトルを持っているので、これを2次元のベクトル上に圧縮していきますが、この処理をにt-SNEという手法を用います。詳細はググって見てください。2次元化したあとは、matplotlibで二次元の散布図を書かせる処理を行います。今回は個々の詳細な説明は省きます。
import matplotlib as mpl
from sklearn.manifold import TSNE
import pandas as pd
vocab = list(model.wv.vocab)
X = model[vocab]
tsne = TSNE(n_components=2)
X_tsne = tsne.fit_transform(X)
df = pd.concat([pd.DataFrame(X_tsne),
pd.Series(vocab)],
axis=1)
df.columns = ['x', 'y', 'word']
from matplotlib.font_manager import FontProperties
font_path = '/usr/share/fonts/truetype/takao-gothic/TakaoGothic.ttf'
font_prop = FontProperties(fname=font_path)
mpl.rcParams['font.family'] = font_prop.get_name()
fig = mpl.pyplot.figure(num=None, figsize=(40, 30), dpi=80, facecolor='w', edgecolor='k')
ax = fig.add_subplot(1, 1, 1)
ax.scatter(df['x'], df['y'])
for i, txt in enumerate(df['word']):
ax.annotate(txt, (df['x'].iloc[i], df['y'].iloc[i]))
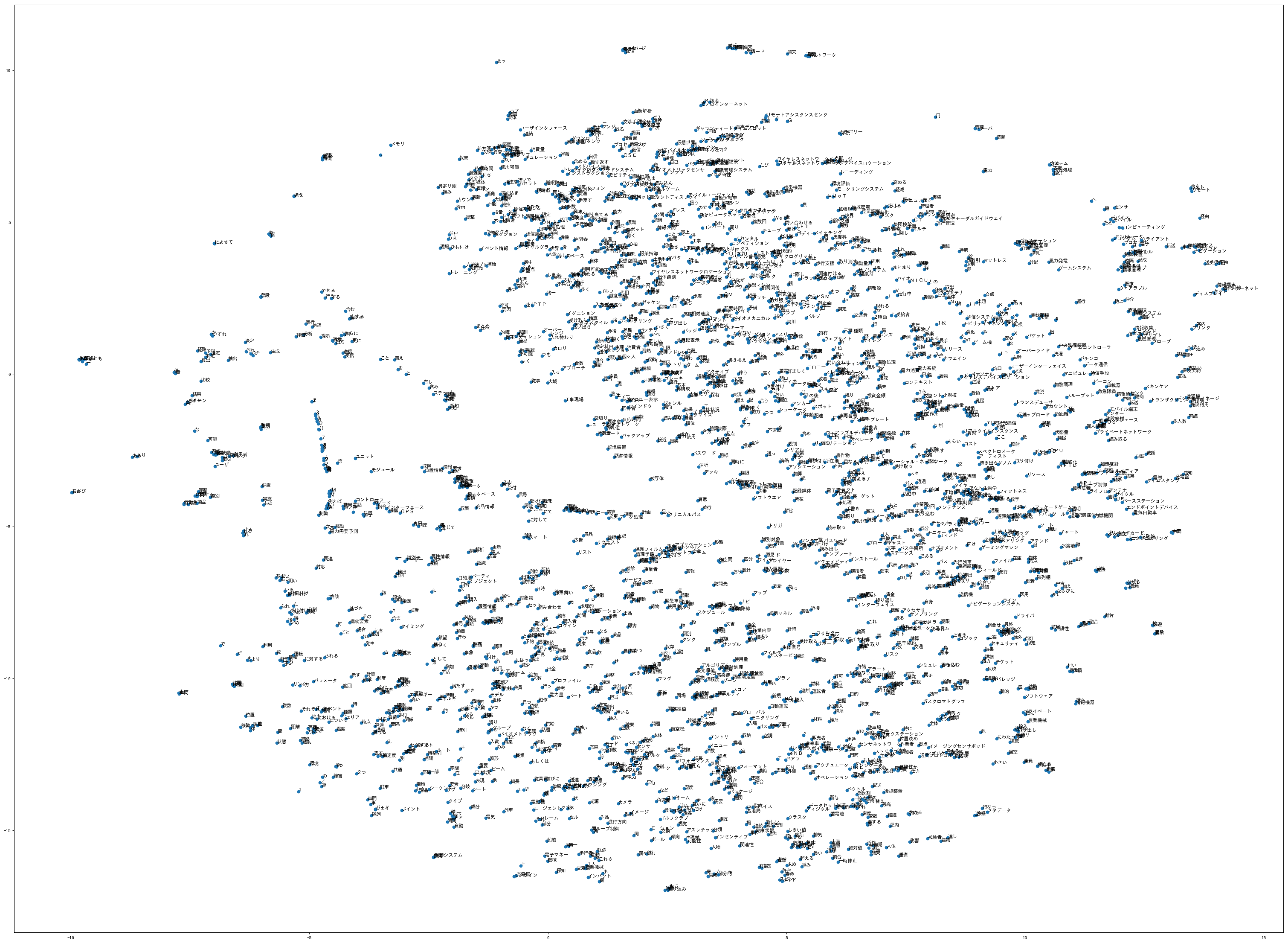 とりあえず雰囲気だけ。こんな感じで出力されます(画像をクリックすると多少高解像度の元画像が表示されます)。
とりあえず雰囲気だけ。こんな感じで出力されます(画像をクリックすると多少高解像度の元画像が表示されます)。元のテキストデータさえ取得できれば、処理自体は10分程度であり、Jupyter Notebookのファイルにしておけば何度でも使い回しが効きます。前回までの単語の頻度分布と組み合わせれば、上のようなごちゃごちゃした図ではなく限られたキーワードの類似度の関係を描くこともできます。どうでしょう、こうなると多少使えそうに見えますか。そこそこ使えそうと思う方、全然使えねぇと思う方、色々かと思います。
そこそこ使えそうと思った方、今回のサンプルは分かり易くするためかなり適当です。データも全文を持ってきたほうが良いかもしれませんし、形態素もMecabではなく、技術ワードに向いたtermmiを使ってみるのもよいかもしれません(Patentfieldの方がDockerファイルを作成されています)し、品詞を絞るのも良いかもしれません。まぁ、商売として特許分析サービスを提供するのでなければ、この辺のこだわりは自分の判断で必要に応じて試行錯誤してみるのが良いと思います。調査や分析でなんらかの効率化に使えないかなというケースが殆どかと思いますので、あまり試行錯誤に時間をかけるのも本末転倒です。
word2vecはitem2vecとしての応用の可能性もあるので、読み込ませるスペース区切りのテキストデータは様々な応用が可能です。例えば、FタームやFI等の特許分類をスペースで区切って読み込ませれば分類間の相関性のマップも描かせることができるでしょう。あるいは自分の独自分類や特許分類と出願人等をスペースで区切って読み込ませれば分類と出願人間の相関性のマップも描かせることができるでしょう。共同出願人をスペースで区切って読み込ませれば共同出願の相関性のマップも描かせることができるでしょう。このように工夫により応用範囲は様々です。商用データベースを使わなくてももっと特許データの入手が楽にできるようになれば良いのですが。
ここまでで件の特許データを使って、自然言語処理を学ぼう!というデータ分析の勉強会の一日目の内容までたどり着けたでしょうか。
CNNとRNNの活用に関わる部分については、気が向けばぼちぼち記事にしていこうかと思います。