さて、前回に続いてOpen Refienの出願人名名寄せ処理の実力のチェック。
前回は英文の出願人名でなかなか良い結果がでましたが、今回は中国語出願人名を見ていきます。
利用するデータはこちらの電池系の中国出願人名になります。
| 出願人 |
| 奇瑞汽车股份有限公司 |
| 三星SDI株式会社 |
| 三洋电机株式会社 |
| 三洋电机株式会社 |
| 三星SDI株式会社 |
| 深圳富泰宏精密工业有限公司 |
| 松下电器产业株式会社 |
| 三洋电机株式会社 |
| 苏州宝时得电动工具有限公司 |
| 东莞新能德科技有限公司 |
| 刘立文 |
| 住友化学株式会社 |
| 华南理工大学 |
| 深圳市崧鼎实业有限公司 |
| 锂电池科技有限公司 |
| 深圳市创明电池技术有限公司 |
| 萨斯特茨维考工业有限公司 |
| 东莞新能源科技有限公司 |
| 株式会社日立制作所 |
さて、このデータをOpen Refineに取り込んでいきます。
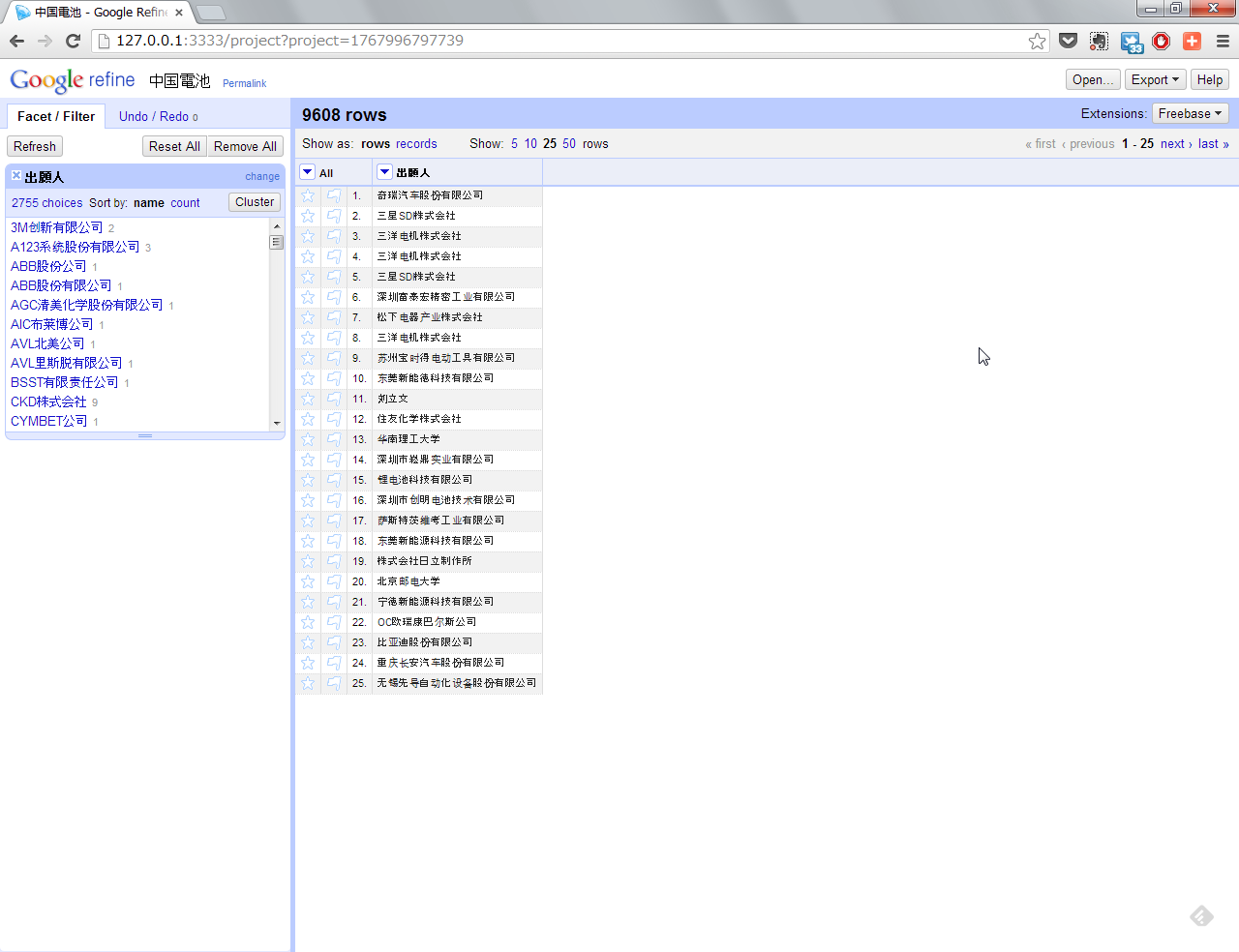
取り込んだのが、この状態。
ここから、前回と同様にText Facetを選択して、ClusteringでMetaphone3を選択するとこのようになります。
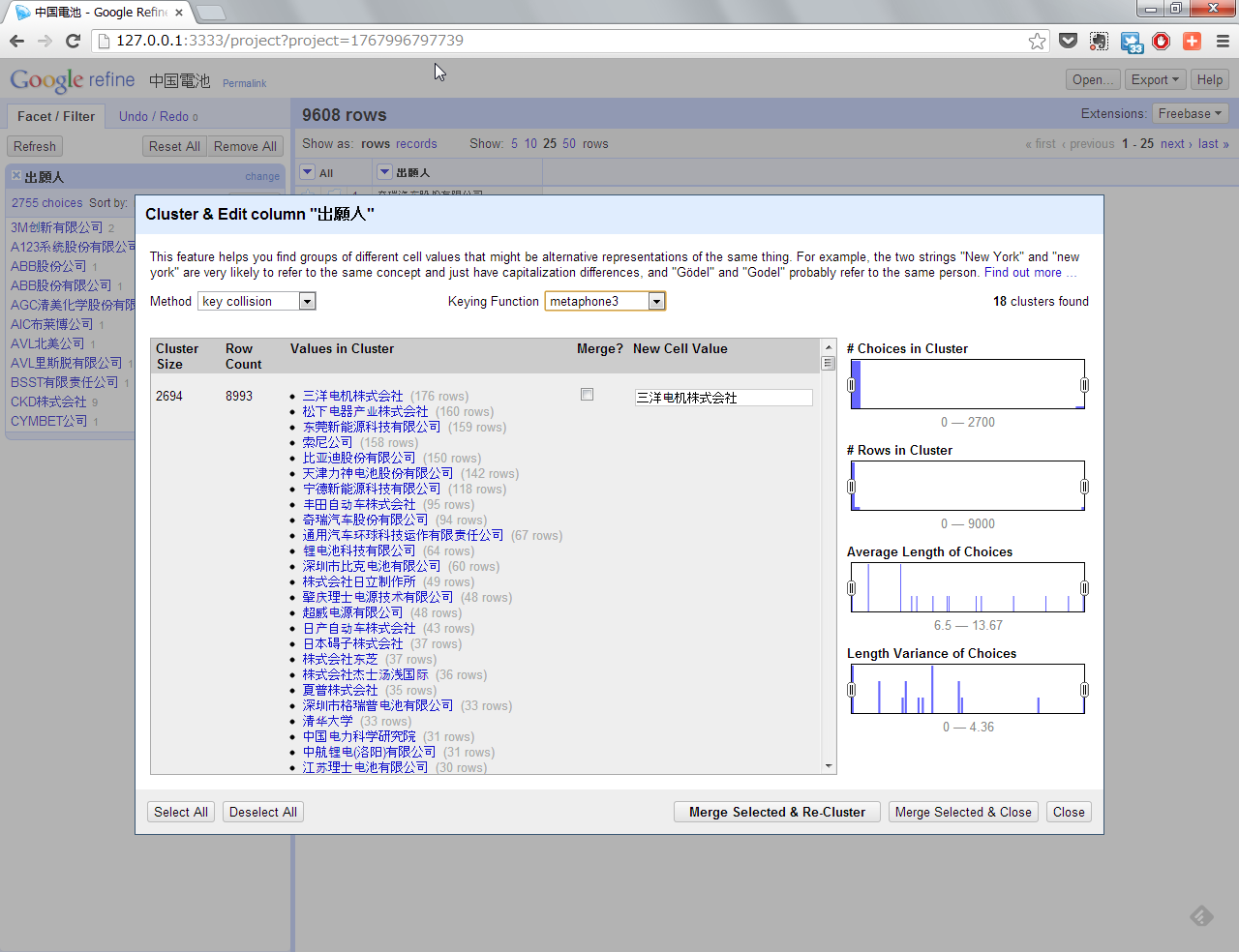
どうしようもないですね。ClusteringでKey Collision系の処理は軒並みダメです。
Key Collision系は英文(Word毎にスペースが入る文)向きで、中国語や日本語のような文には向かないようです。
そこで、nearest neighborのlevensteinを選択してみます。調整値はデフォルトで。
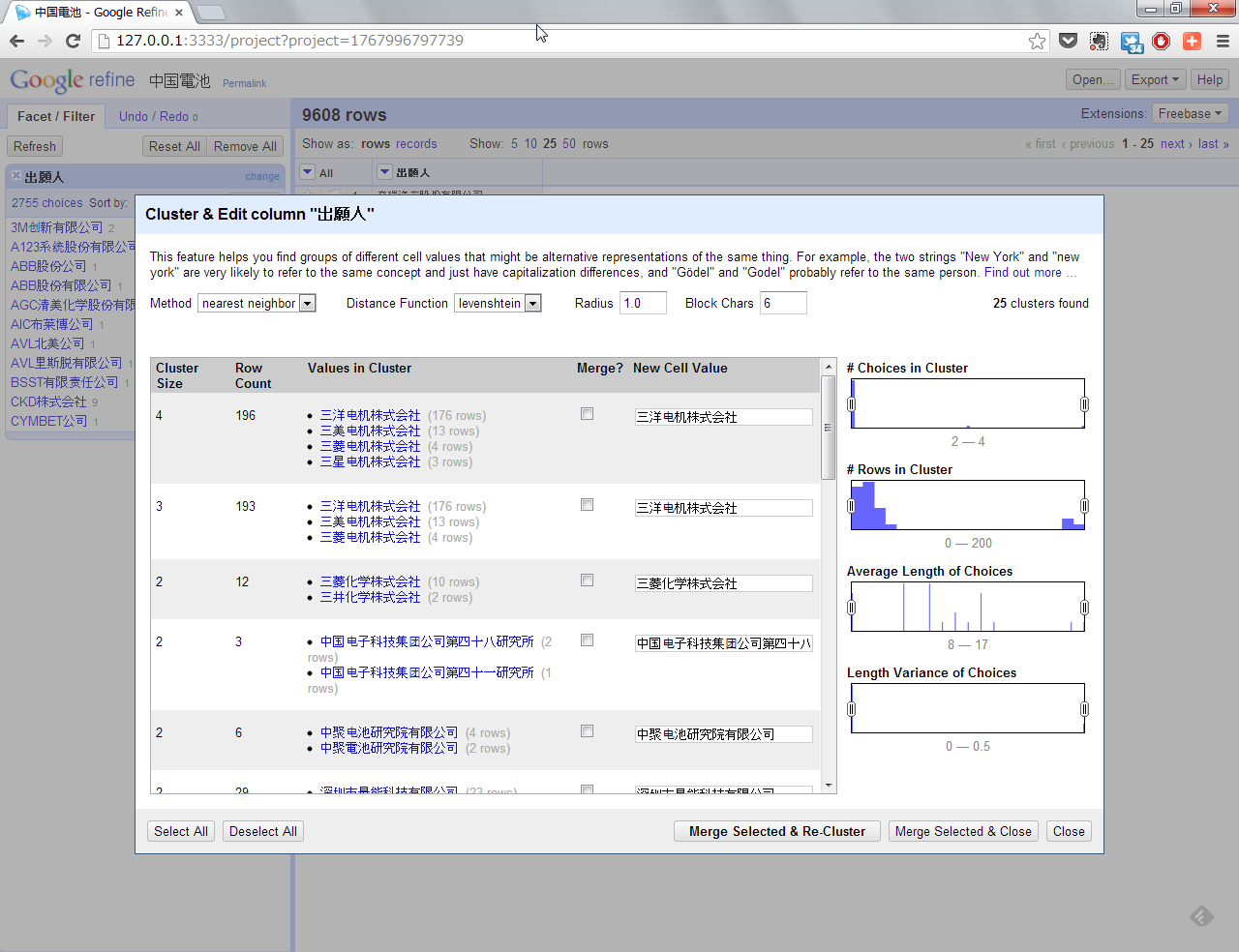
前回の英文と比較するとアレですが、ある程度のレベルで似た文字列の出願人名を名寄せ候補として提示してくれます。後はどれを採用するか個別に選択することになります。まあまあ使えるという結果です。日本語の出願人名の場合にも同様の感覚で使えるでしょう。
さて、一年がかりのOpen Refineでの名寄せ処理の検討でしたが、英文の場合はかなり使え、中国語の場合はそこそこ使えるという結果になりました。発明者名の名寄せの場合も似たような感覚で使えるでしょう。
Open Refineはまだまだ奥が深いのですが、とりあえず、次回はOpen Refineから離れて別の話題にしていきます。